ディープラーニングを「猫/犬の判定」で超やさしく(具体例つき)
目的はシンプルです:正解に近い出力を出すように、内部のつまみ(重み)を自動で調整し続ける仕組みを理解します。
1全体の流れ(ここが核)
何が「賢さ」かというと、内部の重み(つまみ)をうまく調整して、損失(外れ点数)が小さくなる状態を作れることです。
2重み(weight)って何?(唐突にならない説明)
画像を見て猫/犬を判断するとき、人は「耳の形」「鼻」「ヒゲ」「体の輪郭」など、
いろんな手がかりを無意識に見ます。
AIも同じで、たくさんの手がかり(特徴)を見ますが、
どの手がかりをどれだけ重視するかを数字で持っています。これが重みです。
超身近なたとえ:味付けの「分量」
- 材料(入力)= 塩・しょうゆ・砂糖…
- 重み= 「塩は少しで効く」「砂糖はこのくらい」みたいな分量
- 出力= 最終的な味(甘い/しょっぱい など)
重みがズレると「しょっぱすぎる」みたいに、判断もズレます。
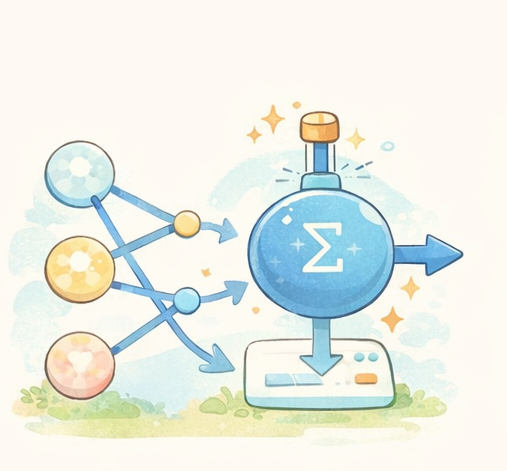
数式はこうなる(中身は単純)
だいたいこんな計算を大量にやっています:
y = w1×x1 + w2×x2 + ... + b
w:重み(重要度のつまみ)
b:バイアス(下駄)
重要なのは「w を少し変えると、出力 y が変わる」という点です。
学習とは「重みを当たりやすい値に寄せる作業」です。
だから次の「損失(外れ点数)」が、重みを直すための“指標”になります。
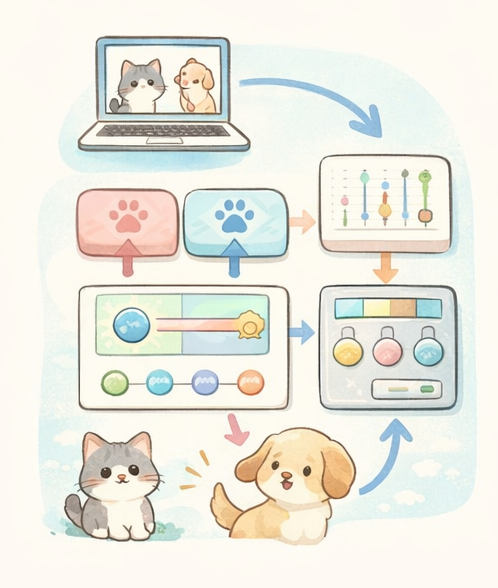
3推論(当てる):いまの重みで「猫っぽさ/犬っぽさ」を出す
推論の意味
いまの重みで計算した結果として、
「猫の確率 0.8 / 犬の確率 0.2」みたいな値が出ます。
ここではまだ「当てただけ」で、良し悪しは判断していません。
当てた結果が「どれだけ正解からズレたか」を、数字でハッキリ決めます。
4損失(loss)=“外れ点数”(抽象じゃなく数値で理解)
損失は一言でいうと 「間違いに対する罰点」です。
そして重要なのは、損失が重みの調整量を決める基準になることです。
具体例:正解が「猫」のとき(猫=1, 犬=0 だと思ってOK)
| 推論の出力(猫っぽさ) | 人間の感覚 | 損失(罰点)のイメージ |
|---|---|---|
| 0.95(猫95%) | ほぼ当たり | 罰点は小さい(ちょい調整) |
| 0.60(猫60%) | 当たってるけど自信ない | 罰点は中くらい(そこそこ調整) |
| 0.20(猫20%) | ほぼ外れ | 罰点は大きい(大きめに直す) |
| 0.01(猫1%) | 大外れ | 罰点は極大(強く直す) |
「なぜ損失が必要?」をさらに噛み砕く
単に「当たった/外れた」だけだと、直し方が分かりません。
でも損失があると、「0.60は少し直す」「0.20は大きく直す」みたいに、直す強さが決められます。

- 今の結果がどれだけダメかを「数」で決める
- 重みを「どれくらい」「どっちに」直すかの材料にする
5学習(直す):損失が減るように重みを少し動かす
やることは単純
- 推論する(猫っぽさを出す)
- 損失を計算する(外れ点数)
- 損失が減る方向を計算する(勾配)
- 重みを少し変える(更新)
これを何千回・何百万回と回して「当たりやすい重み」に寄せます。
「勾配」って何?(難しい言葉を優しく)
勾配は「こっちに動かすと損失が下がる」という方向案内です。
例:味がしょっぱければ「塩を減らす方向」が勾配、薄ければ「塩を増やす方向」が勾配。
AIはそれを数学で自動計算して、重みを少しずつ動かします。
学習で調整しているのは「重み」です。
だから、重みの説明が弱いと学習が何をしてるか分からなくなります(さっき直したのはそこ)。
6バッチ学習:まとめて見てから1回更新(安定させる工夫)
1件ずつ見て毎回更新するとブレやすいので、たいていは小分け(バッチ)で学習します。
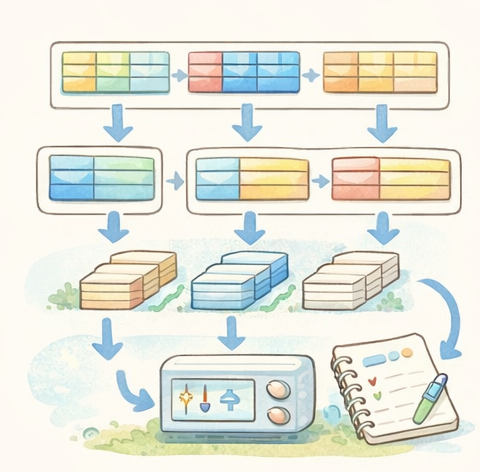
- バッチ:まとめて処理する小分け
- イテレーション:バッチ1つ処理して1回更新
- エポック:データ全体を1周
71行ずつの超やさしい辞書
※このページの理解に必要なものだけ、短くまとめています。
推論(inference)
いまの重みで計算して「猫っぽさ/犬っぽさ」を出すこと。
重み(weight, w)
手がかり(特徴)をどれだけ重視するかの“つまみ”。
バイアス(bias, b)
最後に足す“下駄”。全体の基準点をずらす調整役。
損失(loss)
正解からのズレを数値にした“外れ点数”(小さいほど良い)。
勾配(gradient)
損失を減らすために、重みをどっちに動かすかの“方向案内”。
学習(training)
損失が小さくなるように、重みを少しずつ直し続けること。
バッチ(batch)
学習データを小分けにした1セット。
イテレーション / エポック
イテレーション=バッチ1回→更新1回、エポック=全データ1周。
「損失が小さい=正解に近い」なので、学習は損失を減らす“ゲーム”だと思うと理解が速いです。
No responses yet